How Local Vision Language Models Can Transform Security Cameras Without Cloud Dependency

Security cameras are everywhere, but the intelligence behind them hasn't changed much in years. Most systems still run the same playbook: motion detection, basic object classification, and a flood of alerts every time a tree branch moves. Ring called notification fatigue "one of the most common customer frustrations." Research from Nielsen Norman Group found that users don't just get annoyed by irrelevant alerts, they revoke notification permissions entirely.
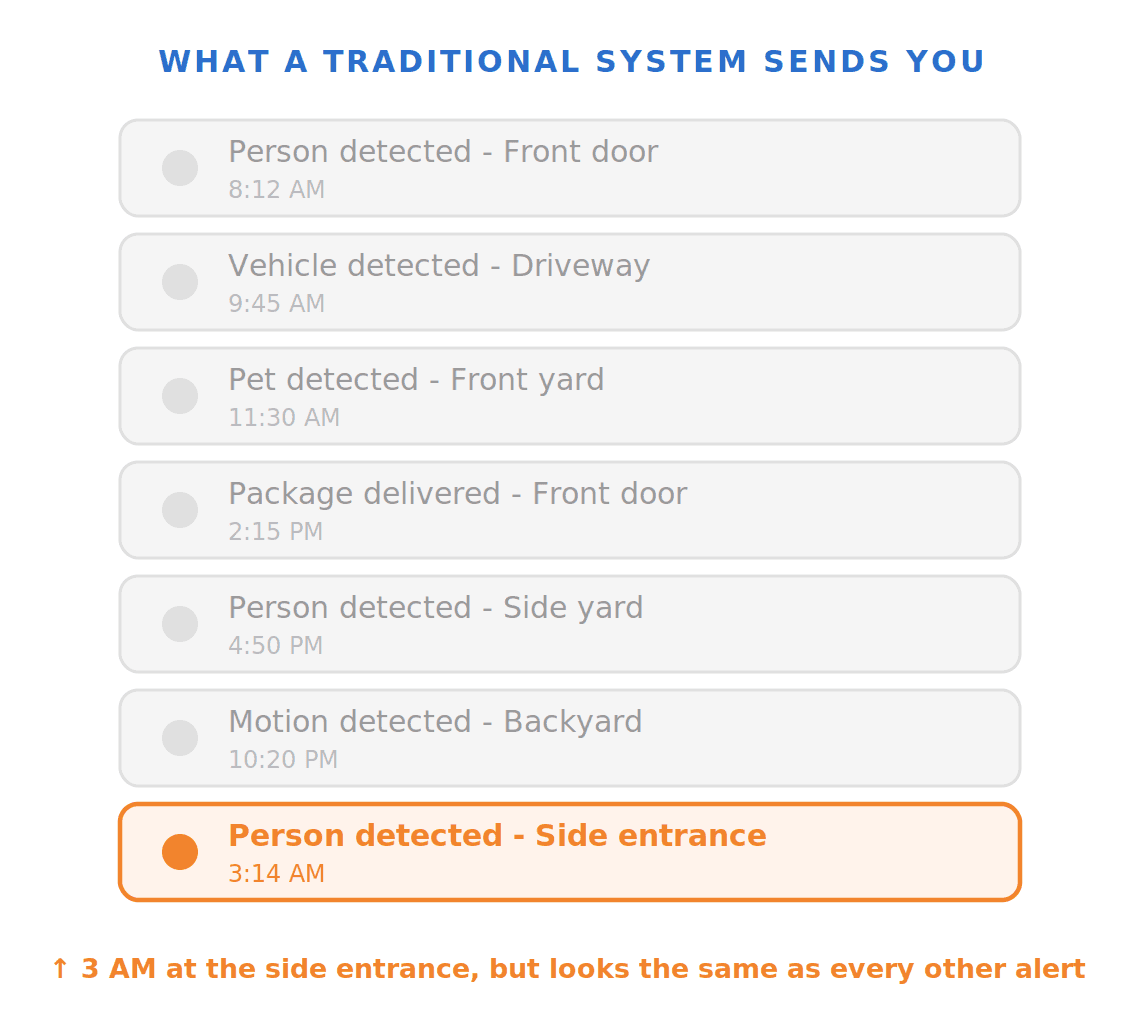
Professional monitoring services exist in part because providers know this happens. When an alarm triggers, a central station calls the homeowner. Some providers have humans review footage before dispatching authorities. That entire layer of labor exists because the camera can't tell the difference between a real threat and a tree branch.

Traditional cameras can tell you "person detected," but they can't reason about context. A person on the sidewalk at noon is not interesting. The same person lingering near your back door at 2 AM is a completely different story. Current systems treat both identically.
Vision Language Models (VLMs) close that gap. Instead of just detecting objects, a VLM reads and understands what's happening in a scene: who is there, what they're doing, whether the situation is routine or suspicious, and whether it warrants an alert. That shift from detection to understanding is the difference between a system that floods you with notifications and one that only speaks up when something actually matters.
This post walks through what it takes to bring VLMs to security cameras in production: the model, the data, the benchmarks, the deployment challenges, and why running this locally on device is the path that actually makes sense.
Our Approach: A Small, Fine-tuned VLM
You could bring VLM intelligence to cameras through cloud APIs, or you could run the model locally on device. We chose the local path, for both product and technical reasons.

Scalable cost structure. Cloud-based VLM inference is expensive as the number of cameras scales (we break down the math later in this post). A small on-device model turns what would be a recurring per-camera API cost into a one-time hardware investment. The core intelligence runs locally at no marginal cost per camera, which fundamentally changes the economics for both consumers and providers.
Product form factor. A small VLM enables an interesting product category: the AI camera hub. A compact device, roughly the size of a small router, that adds VLM-level understanding to any standard video feed from your existing cameras. No camera replacement, no cloud dependency for core functionality. An intelligence layer that plugs into what you already have.
Privacy by architecture. When the model runs locally, video never leaves the premises. This isn't a privacy policy, it's a physics constraint. There's no cloud upload to opt out of because there's no cloud upload. For the significant number of consumers who cite privacy as their primary barrier to smart camera adoption, this is the only answer that fully resolves their concern.
Reliability. No internet dependency means no downtime during outages and no latency spikes. Even without connectivity, the system continues running and stores all analysis results locally on the hub. When the connection comes back, everything is there. Security is one domain where "it works offline" is a requirement, not a feature.
Naturally, a sub-5B parameter model won't match a frontier model on general intelligence and reasoning. But a small model doesn't have to be a general-purpose model. We use a sub-5B VLM post-trained on real-world security footage with domain-specific alignment. Then we have a small model that can match frontier performance on the one domain it's built for. Let's see some benchmarks.
Benchmarking
Claiming a VLM understands security footage is easy. Evaluating its performance on real-world scenarios is a different problem.
Building Our Evaluation Set
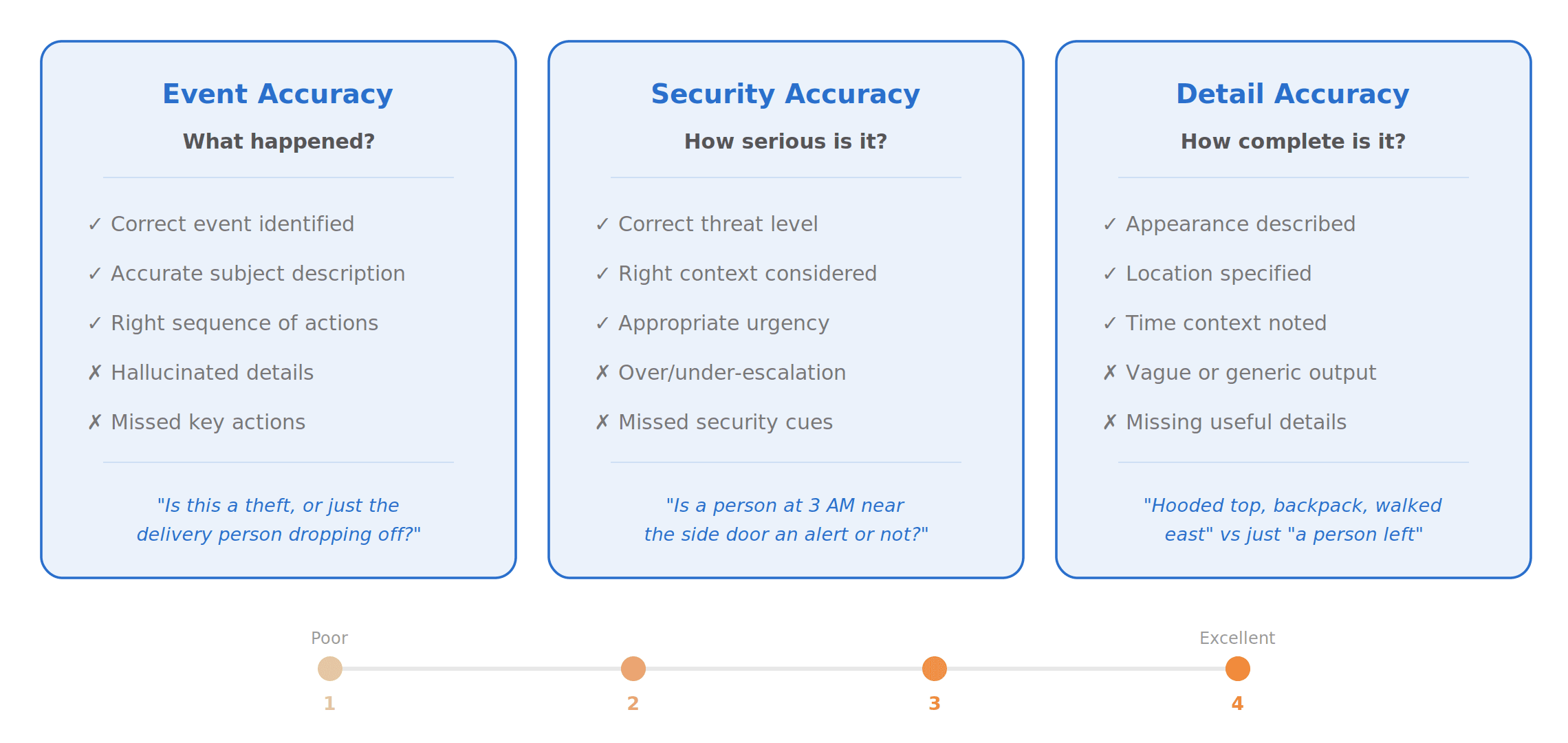
Existing smart home benchmarks like SmartHome-Bench from Wyze mostly evaluate models through question-answering tasks, which only captures part of the problem. For security, a model needs to both identify whether something is security-relevant and summarize what happened accurately and completely. We needed a benchmark that measures both security accuracy and summary fidelity.
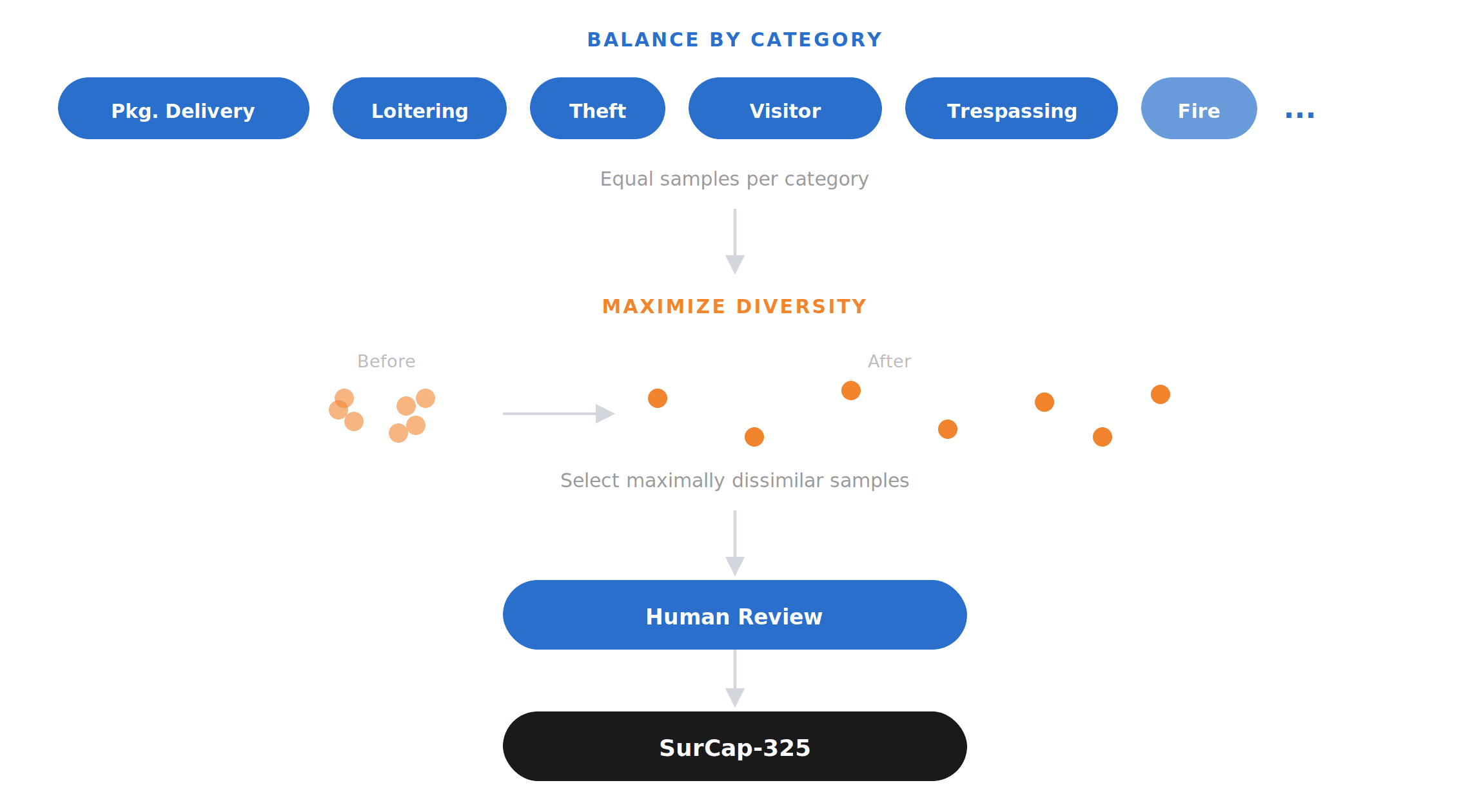
We built SurCap-325 around two principles: balance and diversity. We grouped videos by event type (theft, package delivery, loitering, visitor approach, and other home-security scenarios) and set target sample counts per category. This ensured the benchmark wasn't dominated by a few frequent classes and instead reflected a controlled distribution across the kinds of events we care about.
Within each category, we optimized for diversity. We embedded the human annotations into a semantic feature space and selected samples to maximize dissimilarity across the set, so the benchmark covers as many distinct situations as possible rather than repeatedly testing near-duplicate clips. This produces a set spanning a broader range of behaviors, environments, camera angles, and contextual conditions.
A final round of human review checked labels, summaries, and event categorization, removing ambiguous or low-quality samples before finalization. The result is a test set designed to evaluate real-world security understanding in a balanced, diverse, and reliable way.
Benchmark Results
We evaluated our fine-tuned models against frontier cloud models and larger open-source VLMs on SurCap-325, our security camera captioning benchmark measuring event accuracy, security relevance, and detail quality. Two comparisons matter here.
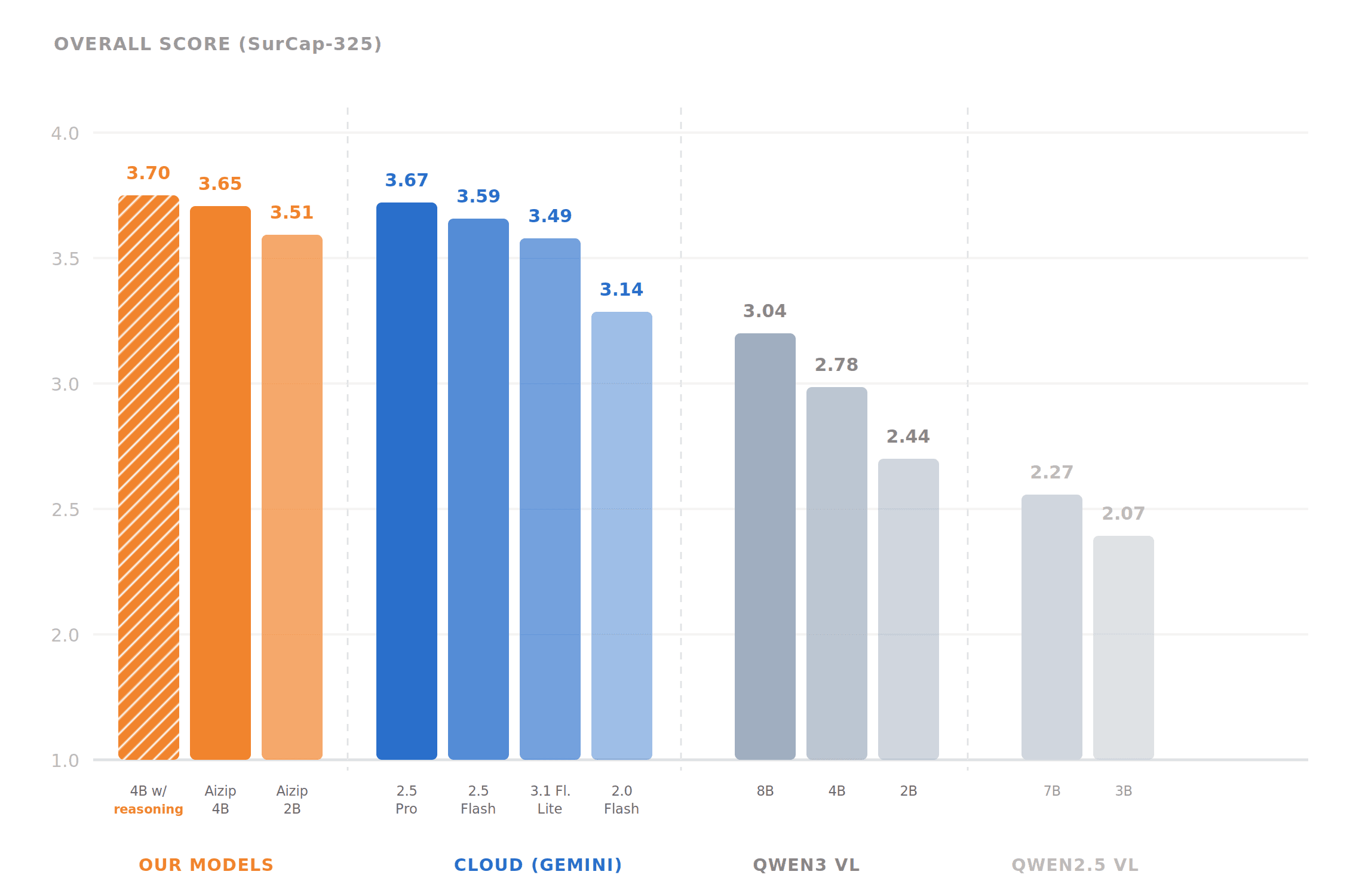
vs. cloud (Gemini). Gemini Flash is the model most teams would realistically deploy in production for cost and speed. Our best fine-tuned model (3.70 overall, 3.88 security accuracy) outperforms Gemini 2.5 Flash (3.59, 3.69) and matches Gemini 2.5 Pro (3.67, 3.77). Notably, Gemini 2.5 versions scored higher than newer Gemini 3 and 3.1 releases on our security tasks, suggesting recent architectural changes optimized for general reasoning at the cost of visual grounding precision.
vs. 7-9B local models. Most existing AI camera hubs and local inference setups default to 7B or 8B VLMs because smaller models are generally considered too weak for meaningful scene understanding. Our benchmark challenges that assumption. Off-the-shelf Qwen3VL-8B scored 3.04 overall. Qwen2.5VL-7B scored 2.27. Our fine-tuned models in the 2B to 4B range (scoring 3.47 to 3.70) significantly outperform both, even at half the parameter count or less. This matters for hardware: smaller models need less memory and compute, which means cheaper edge hardware, lower power draw, and a smaller physical form factor for the product.
How It Works in Practice
Traditional systems would send the same "Person detected" or "Motion detected" alert for all four of these scenarios. Here's what our VLM outputs instead.
[FedEx package delivery - Normal - Footage anonymized]
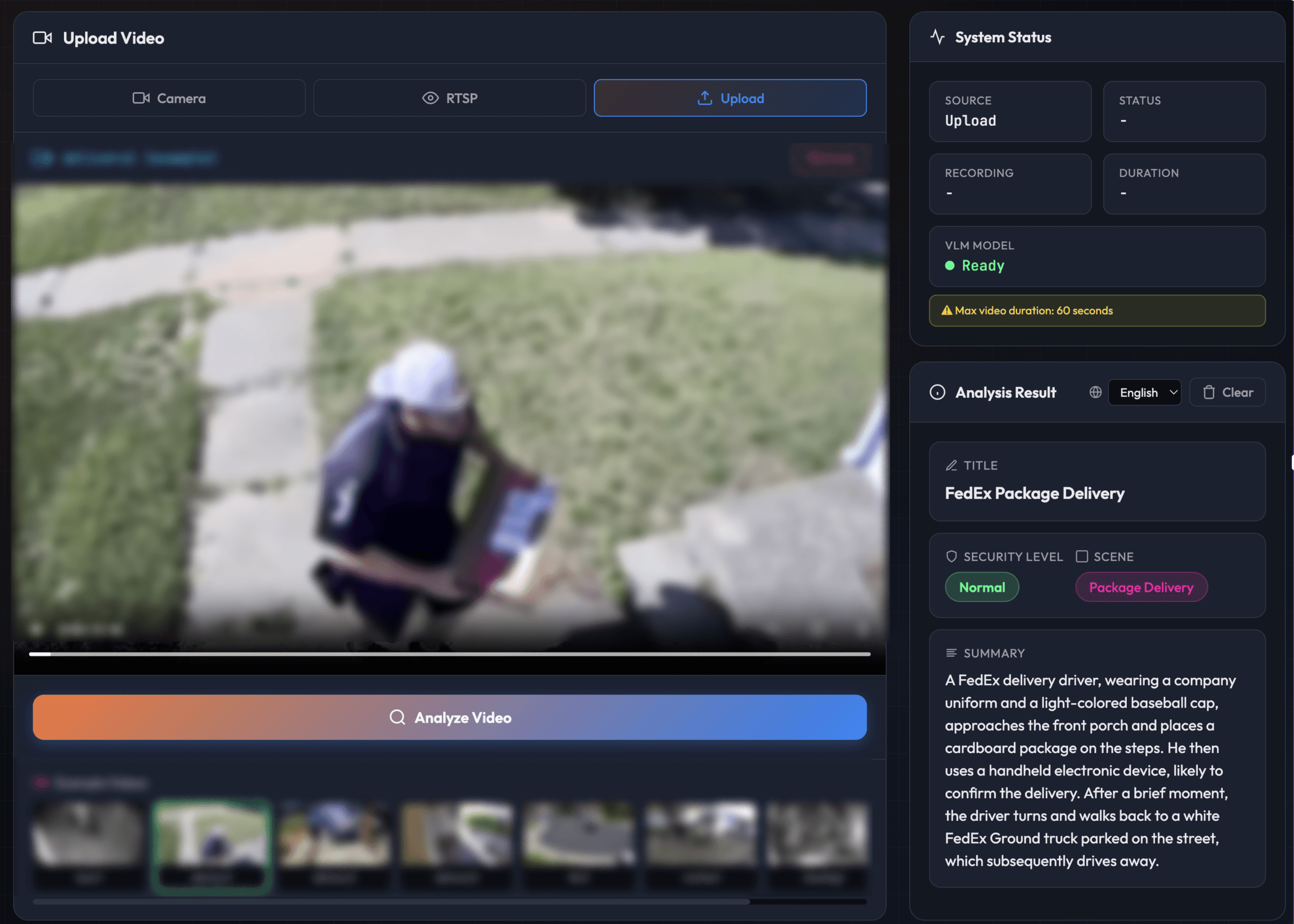
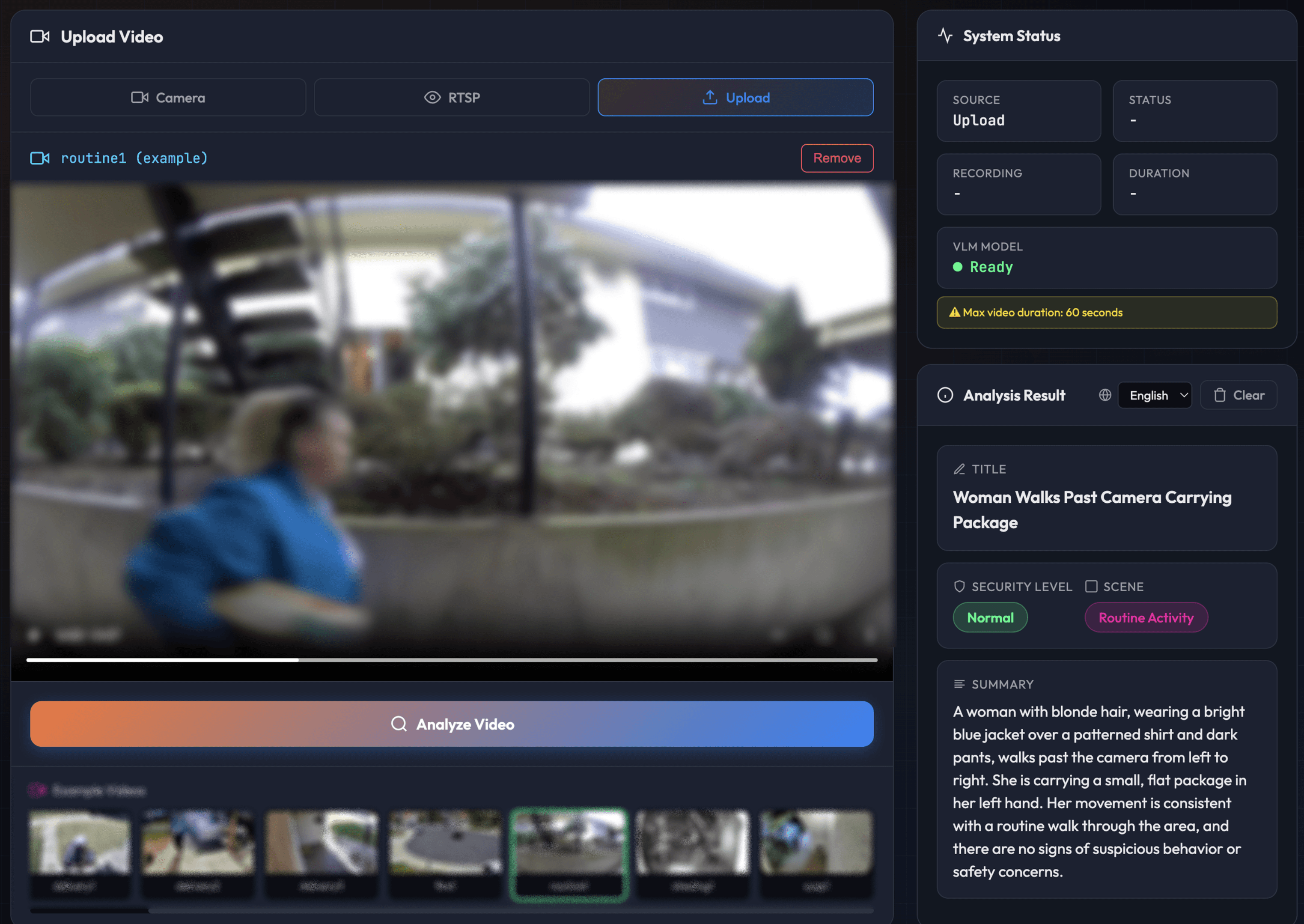
[Random person passed by - Normal - Footage anonymized]
Same location, same object class. One is a routine delivery, one is a crime. The VLM knows the difference.
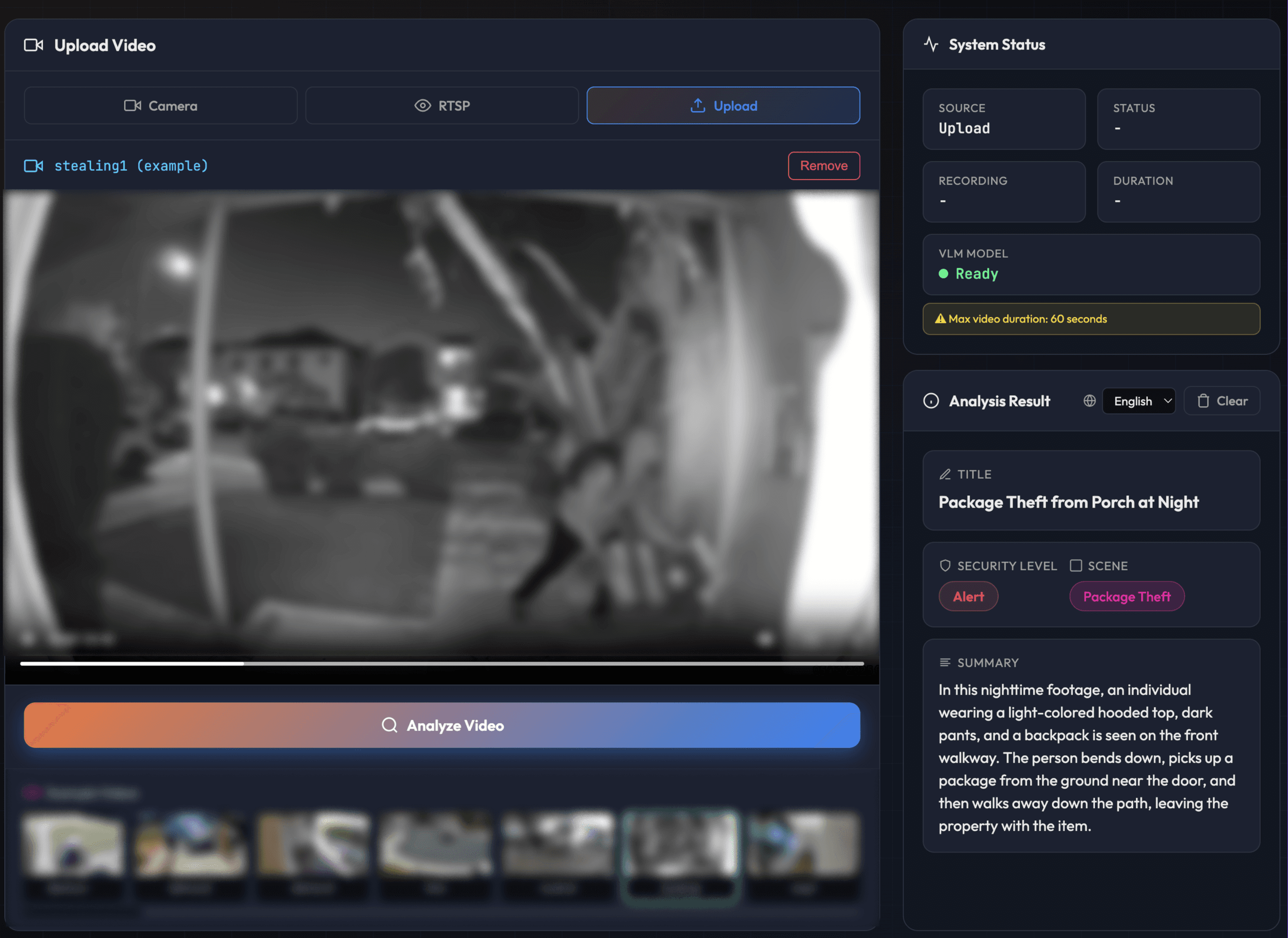
[Random person passed by - Normal - Footage anonymized]
[Unidentified individual stood at the front door - Alert - Footage anonymized]
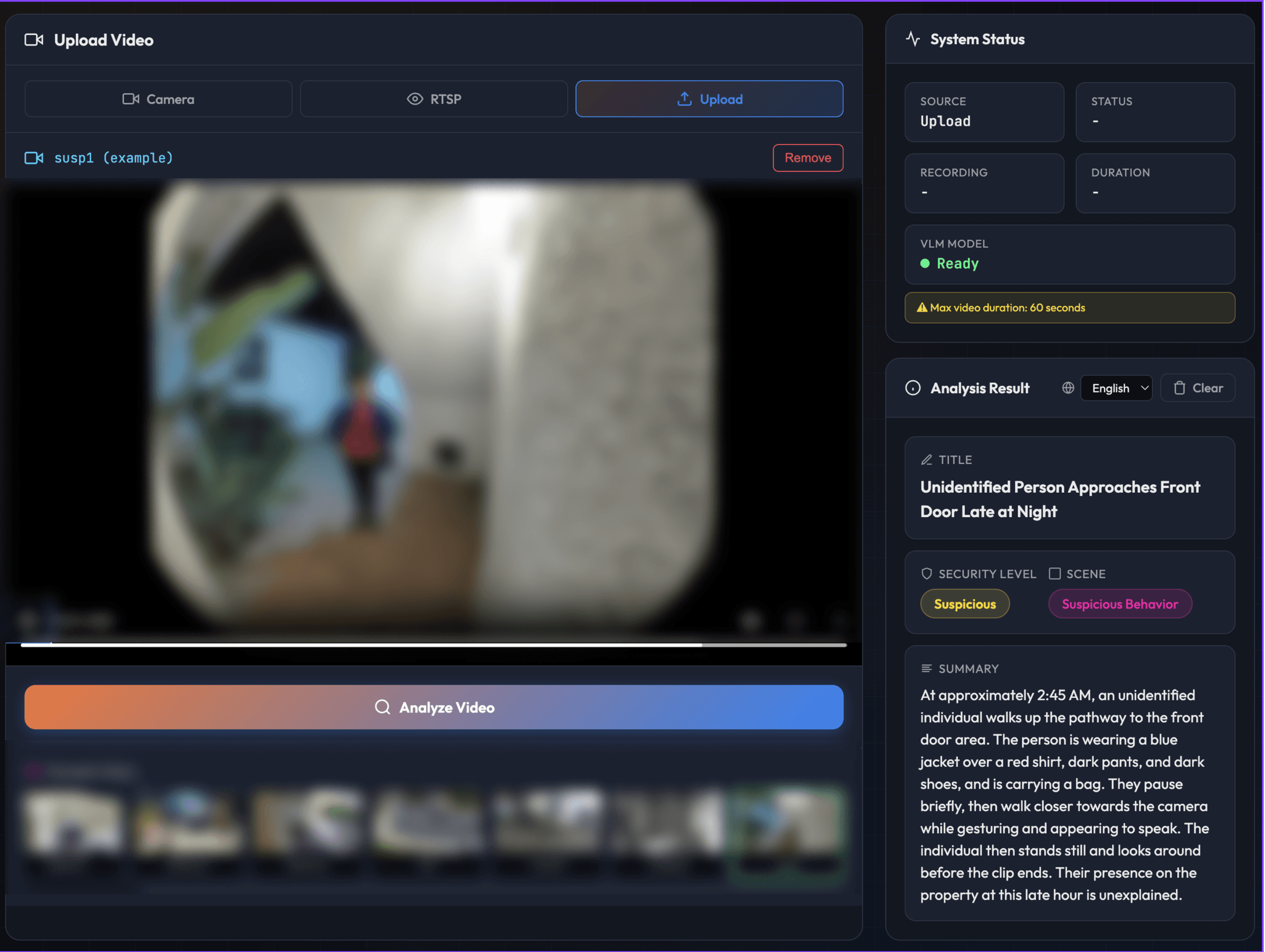
Same detection trigger. One is a neighbor walking by in daylight, the other is someone approaching the front door at 2:45 AM. Context understanding makes huge differences.
Building the Model
We mentioned earlier that we post-train sub-5B VLMs on real-world footage with domain-specific alignment. But how do you actually instill security knowledge into a small model?
Why Synthetic Video Doesn't Work (Yet)
Synthetic data has become powerful for training text and image models. So why not generate synthetic security footage? We tried. The sim-to-real gap in video is dramatically larger than in text or static images.
[Unidentified individual took package - Generated By Veo3]
Real security cameras produce footage with IR noise, lens distortion, and heavy compression artifacts. Real environments are messy: weather, bugs on the lens, cobwebs, headlight glare. Real human behavior is unpredictable in ways that 3D-rendered avatars can't replicate. And security cameras sit at unusual heights and angles that synthetic datasets rarely cover.
When we compared models trained on real-world footage against those trained on generative data, the difference was stark. Synthetically-trained models looked competent in clean conditions but performance dropped significantly on actual security footage. Synthetic data can supplement real data for rare edge cases, but it cannot replace real-world footage as the training foundation. Not yet.
How We Prepared Our Data
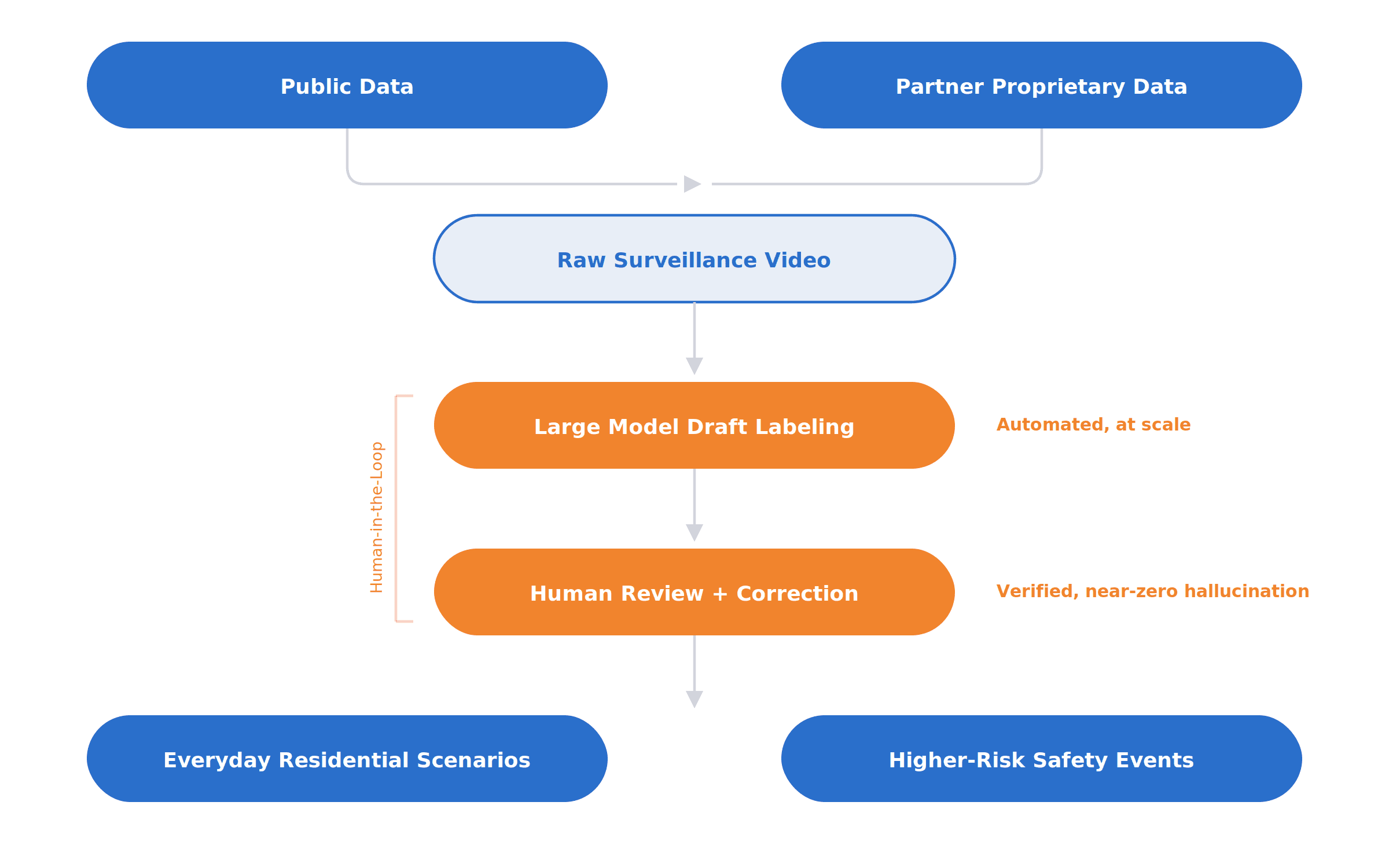
We combined publicly available datasets with proprietary data from partners. But raw surveillance data alone is not enough. In this domain, hallucination is especially costly: a model that confidently invents details is far worse than one that simply says less.
To get as close as possible to a near-zero-hallucination dataset, we built a human-in-the-loop pipeline. Large models first generated draft labels and descriptions, which gave us scale. From there, trained reviewers verified, corrected, and refined those annotations to ensure they matched the footage exactly. This let us combine the efficiency of model-assisted labeling with the precision that security demands.
The final dataset covers everyday residential scenarios (visitors approaching a door, package deliveries, people moving through driveways or side yards, nighttime motion around a home) and higher-risk public safety behaviors (suspicious loitering, trespassing, aggressive actions, attempted theft, and other potentially dangerous events). The goal was not just broad coverage, but realistic coverage of the events operators actually need to understand.
Designing Model Behavior
Fine-tuning isn't just about what the model sees. It's equally about how it responds.

Structured output format. We trained the model with structured instruction-tuning data so that its outputs follow a consistent, machine-parseable schema. Instead of free-form descriptions, the model returns fields such as event type, subject, location, time context, and alert level in a format that downstream systems can consume directly. This makes integration into alerting pipelines, search workflows, and automated response logic straightforward.
Security-relevant captioning style. A single video contains a huge amount of information, but most of it is irrelevant. In security, the goal is to identify the event that matters, not describe everything. We trained the model with carefully designed positive and negative examples to filter out noise and focus on the signal: who is involved, where it is happening, what they are doing, and what makes the event unusual. The result is a captioning style that is concise, contextual, and action-oriented.
Alert categorization. Whether something should trigger an alert depends on more than the visible action. Time of day, location, prior activity, and scene context all matter. We trained the model to pick up on these environmental cues so it can make better judgments about severity. A person walking a dog past a home during the day may need no alert. The same person lingering near a side entrance at 3 AM is a very different event. Grounding classification in context lets the model make more accurate decisions about when to escalate and how serious the alert should be.
The System Design: When Does the VLM Need to Run?
A VLM is powerful, but it doesn't need to run all the time. For most security camera scenarios, a lightweight detection layer, sometimes called Visual Wake Words (VWW), can watch the feed continuously at minimal compute cost and only invoke the VLM when something worth reasoning about appears. Think of how human attention works: notice movement, focus, assess, then relax. Most of the time, nothing is happening, and the system shouldn't burn compute on empty hallways and quiet driveways.
But this is where on-device gets interesting. Because inference is local and essentially free after hardware cost, you're not paying per frame. That means for scenarios that demand it, you can run the VLM continuously, streaming analysis around the clock. For context, even the best traditional monitoring centers take 15 to 45 seconds just to process an alarm signal before anyone is contacted. On-device VLM inference can detect, reason, and alert in seconds with no cloud server roundtrip.
And some scenarios genuinely need 24/7 understanding. Senior care is one clear example: detecting a fall, recognizing distress, or noticing someone hasn't moved in an unusually long time. Continuous fire and smoke monitoring is another: catching early visual signs before a smoke detector triggers, especially in outdoor areas or spaces where detectors aren't present. These cases traditionally required complex heuristic rule systems layered on top of each other. A VLM picks up on context naturally, replacing brittle rules with actual scene understanding.
[Continuous fire monitoring - Footage anonymized]
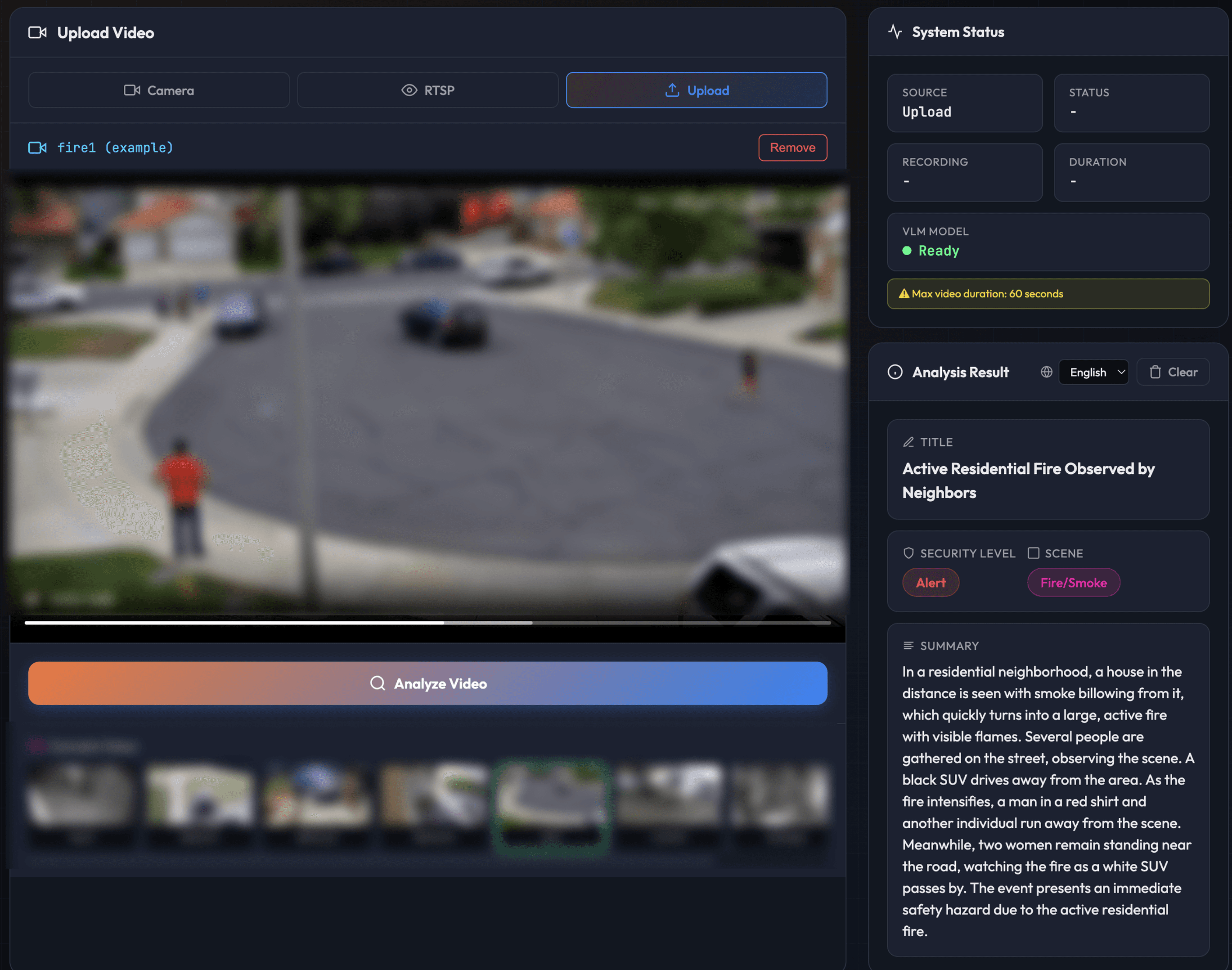
[Continuous human fall detection - Footage anonymized]
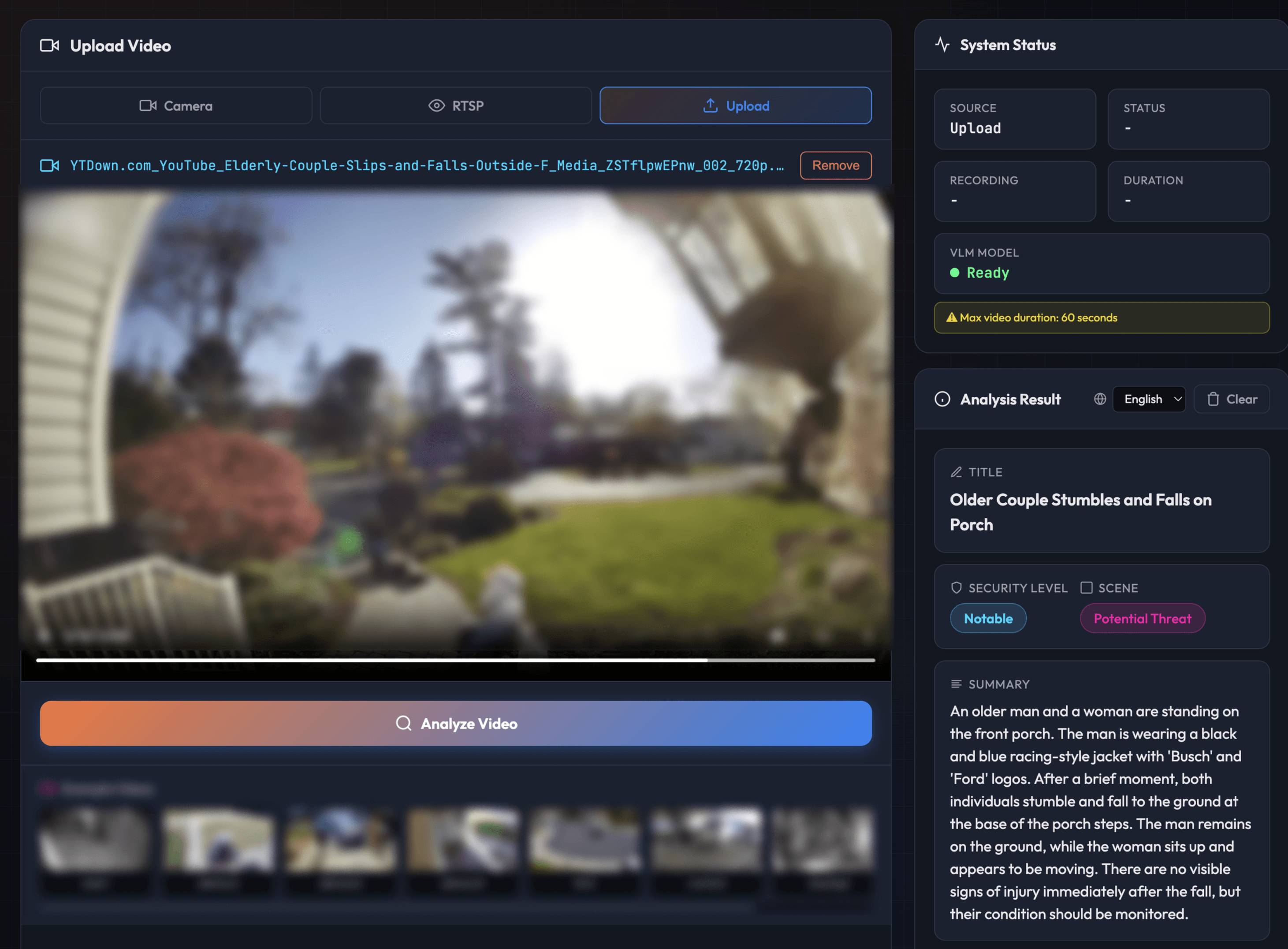
On-device VLM gives you the flexibility to scale from event-triggered analysis to full-time streaming, all on the same hardware. Running locally also has significant implications for privacy and cost.
The Privacy Argument
The security camera industry is already moving toward VLM. Ring uses VLM to generate video descriptions and power their Smart Video Search. Google's Nest cameras use Gemini for descriptive notifications, natural language video search, and daily activity summaries. These are real VLM features, already shipping to consumers. But they all run in the cloud, which means video footage leaves the device.

That matters because privacy remains a real barrier to adoption. Parks Associates found that 25% of potential smart home buyers are held back by data privacy concerns. Among existing owners, 72% worry about data security and 55% worry specifically about hackers. A NIST study found that some consumers deliberately avoid cameras entirely because always-on recording crosses their privacy threshold.
On-device VLM delivers the same capabilities (descriptive alerts, contextual understanding, semantic search) without sending footage anywhere. The video never leaves the premises. Once consumers can get smart camera intelligence without sending footage to the cloud, it becomes a very compelling option.
The Cost Argument
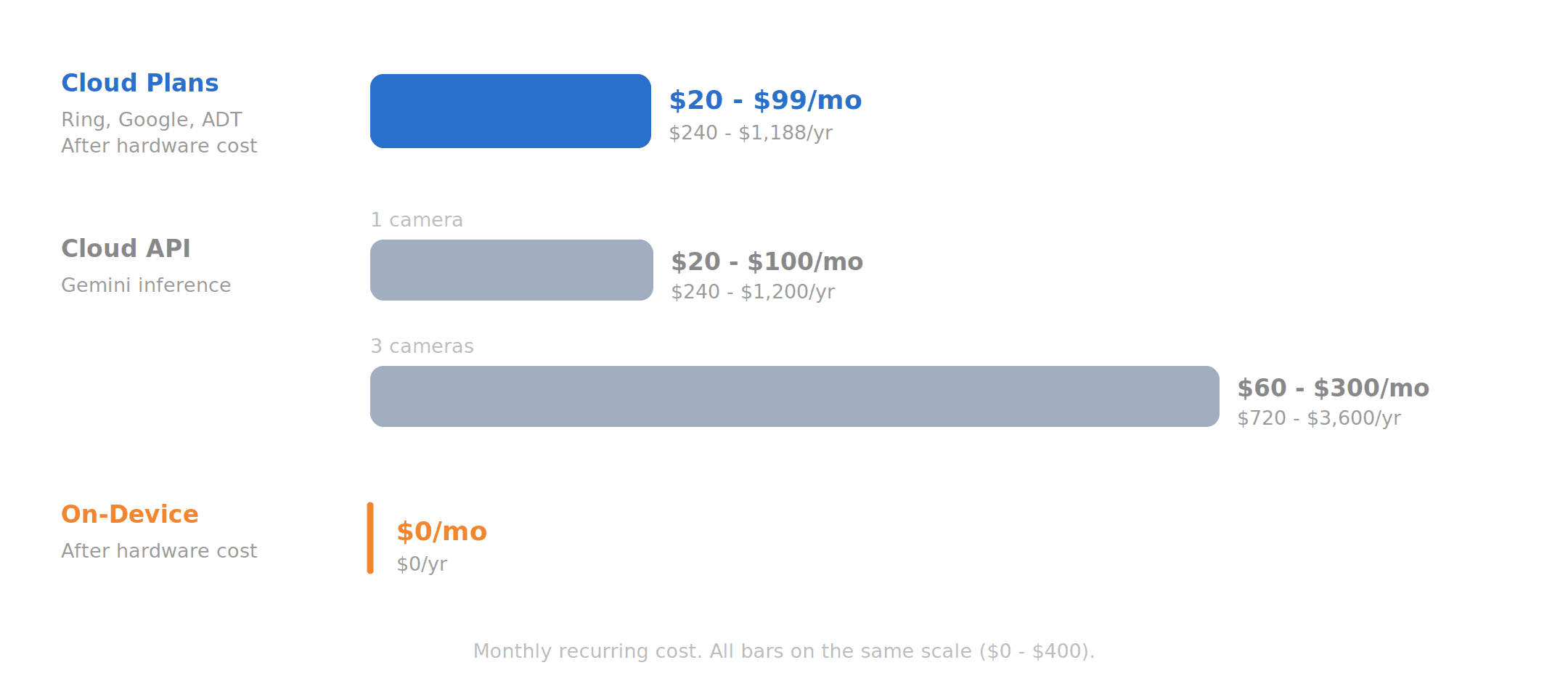
These cloud-based VLM features also come at a price. Ring's AI Pro plan runs $20 per month, their Virtual Security Guard with live agents is $99. Google Home Premium Advanced is $20 per month. Traditional monitoring from ADT runs $25 to $50 with a 36-month contract.
If you tried to build this yourself via API, the math is worse. Video input on Gemini consumes roughly 258 tokens per second. Even at a conservative sampling rate, Gemini Flash costs $20 to $30 per camera per month. Gemini Pro jumps to $80 to $100. Three cameras and you're at $100 to $400 per month just for inference.
On-device flips this. After the one-time hardware cost, most core VLM capabilities that Ring and Google charge $20 or more per month for can run locally without the per-camera recurring fees, without cloud dependency (which means it's always available regardless of internet disruptions), and without footage leaving the premises.
Deployment is The Hardest Part
Running VLMs on device clearly has strong value propositions. So why isn't everyone doing it? Because getting VLMs to run on edge hardware at all is hard, and getting them to run well is even harder.
The Compute Problem
Unlike text-only LLMs, where the bottleneck is generating tokens one by one, VLMs hit a wall at the very first step: processing the image. A single image gets converted into 768 tokens before the model even starts reasoning. To process just one image per second, the system needs roughly 9 TFLOPS of raw compute, and in practice closer to 20 TFLOPS because real hardware never hits peak utilization. Even the most advanced mobile NPUs from Qualcomm and Apple aren't consistently there yet.
Quantization converts the problem from a raw compute challenge into a more hardware-friendly optimization. But VLMs are trickier to quantize than text-only models. The vision encoder degrades differently than the language model, and getting the right balance between accuracy and speed requires custom inference kernels tuned for each hardware platform.
Where the Industry Stands
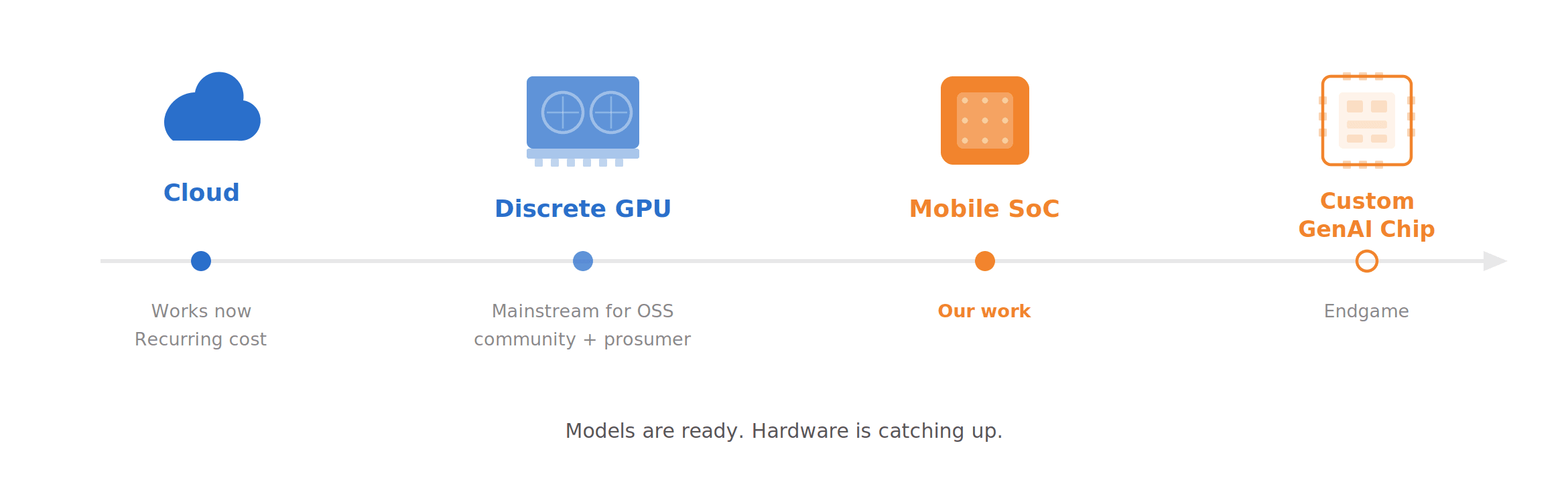
The deployment landscape falls along a clear progression. Running VLMs in the cloud works but carries the cost and privacy issues discussed above. Local inference on 7-9B models using discrete GPUs is already mainstream in the open-source community. Xiaomi's Miloco runs their MiMo-VL 7B this way, and it's where most AI camera hub prototypes sit today. But a discrete GPU means this only remains a project for prosumers or early-stage demos.
We are working on the next phase that can eventually push this solution to the consumer market: running our fine-tuned sub-4B models on mobile SoCs, trading model size for deployment practicality without sacrificing domain-specific quality. The endgame, which we are also working on with our chip partners, is custom generative AI chips purpose-built for this workload, potentially at a bill of materials around $10, which is what makes a consumer-grade price point realistic at scale.
The models are ready. The hardware is catching up, and we don't think it's far off.
What's Next
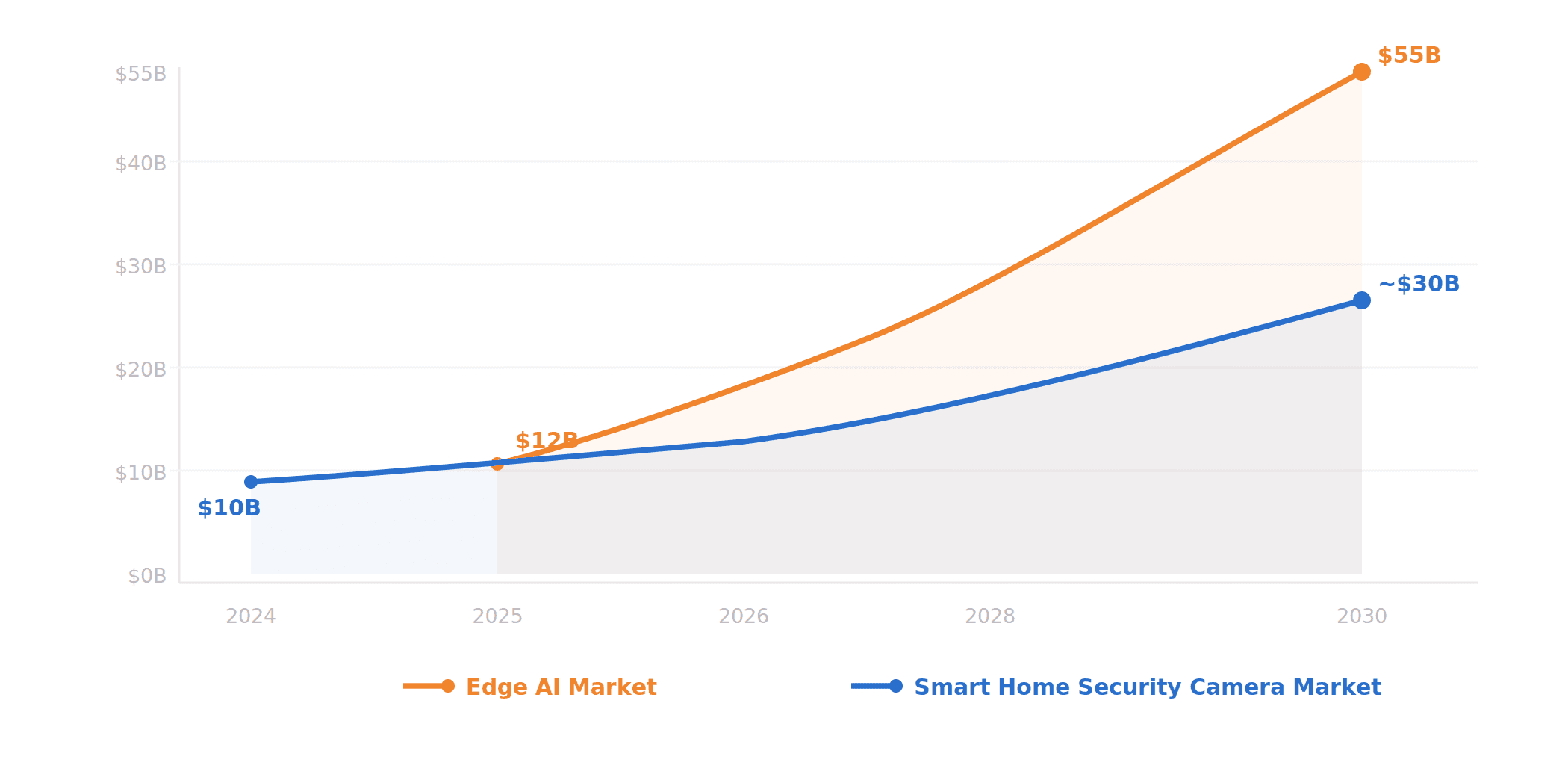
The market is moving in this direction. The global smart home security camera market was valued at roughly $10 billion in 2024 and is projected to grow at over 20% CAGR through the end of the decade. Meanwhile, the edge AI market is on an even steeper trajectory, expected to grow from around $12 billion in 2025 to over $55 billion by 2030. These two curves are converging: consumers want smarter cameras, and the hardware to run AI locally is getting cheaper and more capable every year. AI-powered analytics and subscription-free models are already cited as key growth drivers by multiple industry analysts. We expect to see VLM-powered cameras or AI hubs selling under $200, and eventually sub-$50, very soon.
We see the larger opportunity. The applications extend well beyond home security. We worked with SoftBank to bring bear activity monitoring to Japan, and are working towards retail loss prevention, restaurant safety compliance, and other environments where cameras are deployed but human attention is scarce. On the technical side, we're pushing toward multi-camera reasoning, smarter state machine triggers, deeper integration with smart home ecosystems, and building a complete system where users can semantically search their camera history in natural language.
For years, the security camera industry has been making incremental improvements: better resolution, smarter motion zones, fewer false alerts. VLMs are the first change that makes cameras actually intelligent.
References
Amazon. "Ring debuts Video Descriptions, Gen AI-powered updates on what's happening at home." aboutamazon.com.
Nielsen Norman Group. "Designing Useful Smart Home Notifications." nngroup.com.
Ring. "AI Video Descriptions, AI Single Event Alert and Unusual Event Alert." ring.com.
Ring. "Smart Video Search." Ring Blog, March 2025.
Google. "Gemini for Home Launch." Google Blog, October 2025.
Parks Associates. "Protect the Connected Home: Home Security Meets Personal Privacy." parksassociates.com.
Haney, J. M. et al. "Smart Home Security and Privacy Mitigations." NIST IR 8330, 2020.
Ring. "Protect Plans." ring.com.
ADT. "Monitoring Plans & Security Services." adt.com.
Google. "Gemini API Pricing." ai.google.dev.
Frontpoint Security. "What is Alarm Response Time and Why is it Important?" frontpointsecurity.com.
Grand View Research. "Smart Home Security Camera Market." grandviewresearch.com.
BCC Research. "Global Edge AI Market." bccresearch.com.
SmartHome-Bench. "SmartHome-Bench-LLM." GitHub / CVPR 2025.
Xiaomi. "Xiaomi Miloco." GitHub.